

Columna de Ciencia y Tecnología
Pablo D. Dans
No sé si está cuantificado, seguramente, pero se dice que el ser humano ha hecho más descubrimientos científicos durante el siglo XX que durante el resto de la historia de la humanidad.
Lo que es innegable, es el impacto que tuvieron y siguen teniendo dichos descubrimientos sobre preguntas tan esenciales como ¿quiénes somos?, ¿de dónde provenimos? y ¿cómo somos lo que somos en la salud y en la enfermedad?, los descubrimientos del siglo XX fueron únicos en cantidad, pero sobre todo en su calidad para explicar y generar aplicaciones tangibles que han cambiado nuestra forma de vivir y percibir el mundo, y el universo que nos rodea.
No me gustan los rankings, y tampoco es posible ser exhaustivo, pero no puedo dejar de mencionar avances significativos en el campo de la física que han permitido contestar ciertos aspectos claves del ¿quiénes somos? y ¿de dónde provenimos? Me refiero a la creación de áreas enteras del conocimiento (teoría de la relatividad, mecánica cuántica, reacciones nucleares), a la llegada de técnicas fundamentales para la medicina actual (resonancia magnética nuclear, difracción de rayos-X), y al desarrollo de conceptos tan importantes como la estructura atómica, la deriva continental, o la expansión del universo. En matemáticas, nuevas áreas de conocimiento como aquellas agrupadas bajo la teoría de la computación fueron imprescindibles para el desarrollo tecnológico del siglo XX. Nuevas tecnologías, que con sobradas pruebas nos han cambiado en el plano civilizatorio. Pero para dar respuesta al ¿cómo somos lo que somos en la salud y en la enfermedad?, la biología y sus avances durante el siglo XX han sido sin duda los protagonistas de lujo. Se descubre el primer agente con propiedades quimioterapéuticas (Salvarsán, 1907), y el primero de muchos antibióticos (Penicilina, 1928). En 1922 se aísla y se logra producir insulina. En 1951 se descubre como propagar células humanas en condiciones de laboratorio (Gey 1951), lo que conduce al nacimiento de la biología celular. Un año después, en 1952, se tiene la primera vacuna que fue inoculada masivamente (contra la Polio). Para 1996, y casi totalmente a ciegas, se logra clonar a la oveja Dolly.
Pero de todos estos descubrimientos -intentaré convencerlos- hubo uno madre. Uno fundamental y básico. Uno que fue indispensable para la revolución en la biología. Uno que genera al día de hoy nuevos conocimientos con una velocidad exponencial. Uno que amenaza con cambiarnos, no solo en el plano civilizatorio, sino también y fundamentalmente en lo que devendremos como especie. Me refiero a la entrada en escena de la doble hebra de ADN en la primavera del 53, y cuyas implicancias desarrollaré en los próximos párrafos.
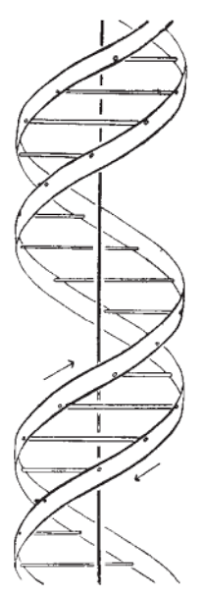
Publicado en la revista Nature, y firmado por Watson y Crick, en menos de una carilla, el artículo que empezaba "deseando sugerir" una nueva estructura para el ADN (ver figura 1), se transformaría sin saberlo en la semilla fundacional para la revolución de 1953, durante la cual nace entre otras áreas la biología molecular. Claro está, que la triunfal llegada de la doble hélice no hubiera sido tal sin los experimentos de Wilkins, Stokes, Wilson, Gosling, y sobre todo la famosa fotografía 51 de Rosalind Franklin, publicados en el mismo volumen de la revista. Allí, quedaron asentados los fundamentos teóricos para entender la replicación de la información heredable, la especificidad y a su vez la gran diversidad genética (basada en las enormes posibilidades de variación en la secuencia), y hasta los mecanismos para la mutación, que debían originarse al producirse apareamientos no canónicos entre las dos hebras y sus 4 bloques de construcción: adenina (A), citosina (C), guanina (G), y timina (T). Allí, en esos días, junto a las teorías de Pauling, también nace la biología estructural que basa el entendimiento de los procesos que dan origen a la vida, en el conocimiento de la estructura molecular de sus componentes: las biomoléculas.
Para llegar a proponer su modelo, Watson y Crick se inspiraron ciertamente en los trabajos de Avery, quien determinó en 1944 que el ADN conformaba los genes, y que este último era la "substancia" responsable de producir los cambios heredables; se basaron en las observaciones de Roger y Vendrely, que reportaron en 1948 que todas las células de una misma especie animal contenían un valor constante de ADN denominado valor C; y se apoyaron en las proporciones medidas por Chargaff, quién en 1949 descubrió que las diferentes especies diferían en su contenido de ADN, pero siempre respetando la regla que asignaba el mismo porcentaje de bloques A y T por un lado, que de bloques G y C por otro.
Una de las primeras contradicciones a la que tuvimos que enfrentarnos se dio a conocer como la paradoja del valor C, originada en la inmensa diferencia en la cantidad de ADN encontrado en diferentes especies. Sin embargo, dicha cantidad de ADN no mostraba relación con la complejidad del organismo. Por ejemplo, el pez salamandra escamoso que puede encontrarse al norte del Uruguay en las zonas pantanosas del Rio Paraná, tiene 20 veces más ADN que el ser humano siendo un organismo claramente más simple desde el punto de vista evolutivo. La paradoja quedó parcialmente resuelta al encontrarse que además de las secuencias de ADN que codifican para proteínas y que llamamos genes, la mayor parte del ADN de nuestras células no codifica aparentemente para nada. Al inicio, se pensó que se trataba de genes jubilados que el organismo ya no necesitaba; o en buen romance, de restos olvidados y a su vez testigos de una larga evolución llena de periplos; y se le denominó ADN-basura (del inglés "junk-DNA"). Así, era fácil justificar que el pez salamandra tuviera más ADN que 20 buenos samaritanos juntos, simplemente porque las células del pez contenían más ADN basura. No fue hasta los años 70 cuando voces disidentes empezaron a cuestionar el término, sugiriendo cambiarlo por el de "ADN no-codificante", dadas las evidencias crecientes de que al menos una porción de aquel ADN-basura era biológicamente activo y funcional (si bien no producía proteínas).
Tuvimos que esperar hasta que salieran a la luz en el 2001 los resultados del proyecto genoma humano para poder cuantificar la magnitud de ese ADN no-codificante. Menos del 5 % de todo el código almacenado en el ADN sirve para producir proteínas (genes), siendo el 95 % ADN no-codificante. Se supo que el código completo está conformado por poco más de 3 mil millones de bloques de construcción, por lo cual unos 150 millones de bloques de construcción están destinados a constituir los aproximadamente 21,000 genes responsables de la producción de 250,000 proteínas diferentes que se encuentran en los seres humanos. Así, toneladas de datos. Uno de los resultados más claros era que parte de ese ADN no-codificante, que llamábamos basura, estaba involucrado en los procesos de iniciación, represión o estimulación de la síntesis de proteínas. En otras palabras, existían secuencias no-codificantes de ADN que eran sitios de unión para las proteínas encargadas de regular la producción. A su vez, aquel ADN no-codificante sí codificaba, pero no para la producción de proteínas, sino para la creación de cientos de moléculas de ARN (pariente del ADN) que también regulan la actividad genómica (y de las cuales, sin ser contadas excepciones, aún poco se sabe).
La primera década del siglo XXI vio la secuenciación de decenas de genomas completos de especies diferentes, y nos tuvimos que chocar nuevamente de frente contra la explicación clásica que atribuía a los genes (las secuencias que producen proteínas) la extraordinaria complejidad de la anatomía, fisiología, inteligencia y comportamiento humano. Resultó que un simple gusano microscópico y transparente (Caenorhabditis elegans) tiene aproximadamente el mismo número de genes que los humanos. Lo que es más, la mayoría de los genes de dicho gusano tienen equivalencia directa con genes humanos. Hoy sabemos que la explicación a las singularidades del ser humano, está escondida en dicho ADN no-codificante, y en el grado de complejidad de una capa extra de información que regula la expresión de los genes y que mencionaré a continuación.
A pesar de todos los avances, no fue hasta el 2012 (¡hace solo 5 años!), con los resultados del proyecto ENCODE (sigla del inglés ENCyclopedia Of DNA Elements), que se pudo cuantificar y afinar la puntería. En realidad, solo el 2.9 % del genoma humano codifica para proteínas y 8.5 % son secuencias blanco para las proteínas de regulación, aunque se estimó que hasta 40 % de la regiones no-codificantes tienen que ver con la regulación de la producción de proteínas y el correcto funcionamiento de los genes. Pero el proyecto ENCODE fue crucial por otros motivos. Por primera vez, y a escala genómica (el ADN de todo el núcleo), se describieron los elementos que forman parte de un capa extra de información que llamamos epigenética. Una información heredable, pero que no está codificada en nuestro ADN. Se trata de una capa de regulación adicional al código genético mucho más flexible y cambiante, capaz de verse modificada en el corto tiempo, en términos evolutivos, que dura la vida de una persona. Dicha capa se ubica literalmente por encima del código genético (del prefijo griego epi, que significa encima), y se manifiesta como pequeñas modificaciones químicas en los bloques de construcción del ADN, o en algunas proteínas encargadas de modificar su compactación y ubicación espacial dentro del núcleo celular [1].
El patrón de modificaciones epigenéticas que cubre nuestro genoma es un código que se hereda, pero que sabemos puede modificarse en la vida de un hombre si se sufre mucho estrés, o de acuerdo a la alimentación, o a la actividad física que se realice. Si un antepasado sufrió hambre durante una época de guerras es posible que su patrón de expresión, regulado por la epigenética, se haya modificado para favorecer la producción de una mayor cantidad de proteínas encargadas de la asimilación de los alimentos y de la retención de las correspondientes calorías. Una vez heredado, un hijo o un nieto que vive una época de bonanza libre de guerras y sobre todo libre de límites en la ingesta de alimentos notará como adquiere kilos fácilmente y engorda por encima de la media. Resulta irónico y hasta contradictorio, que la consecuencia de una hambruna pueda terminar reflejándose, a través de la epigenética, en dos o tres generaciones posteriores con problemas de obesidad y de diabetes. Pero esto es exactamente lo que les pasó a los hijos y nietos de las mujeres que sufrieron el Hongerwinter, la gran hambruna holandesa de 1944. Heredaron lo que yo llamo una epigenética de posguerra.
Lo asombroso del caso, es lo complejo y claramente reciente que resulta para todos, incluso para los expertos, todo este conocimiento. Sin embargo, ha calado muy profundamente en nuestra sociedad. No hay en la historia de la humanidad otro descubrimiento que se haya asimilado y popularizado tan rápido y de forma universal como la doble hélice de ADN y sus implicancias (quizás compitiendo con Internet y las telecomunicaciones en general). Hoy, no hay don o doña del mercado que no sepa que el síndrome de Down es una enfermedad genética, y por ende ligada al ADN. Varios sabrán decirle que se trata de una trisomía, y los más avispados, ubicarlo en el cromosoma 21. Raros son los jóvenes en la playa que no sepan que el cáncer de piel por exposición solar se debe a que estamos dañando el ADN que se encuentra en el núcleo de las células de la epidermis; y a nadie, ni al más común de los mortales, se le ocurre discutir que aquello que suena tan familiar y adorable en la progenie, no fue transmitido por combinación de la información genética ubicada en el ADN de los padres. Pero las aplicaciones van más allá y la revolución del ADN, silenciosamente, se dio en todos los campos. Hoy en día usamos el ADN para todo. Sirve para apresar delincuentes, cotejando ciertas marcas específicas de su secuencia de ADN con las muestras biológicas que siempre quedan en la escena del crimen. Sirve para tipificar los alimentos, y saber si a sus chorizos de cerdo no le han agregado carne de caballo. Sirve para encontrar hijos de desaparecidos, atestiguando maternidad, paternidad o más ampliamente consanguineidad comparando una combinación de marcadores específicos (en el ADN no-codificante) solo presentes en el grupo familiar. Sirve para rastrear los orígenes de los antepasados, logrando explicar porque algún oriental [2] que otro se destaca por su tozudez vasca, por su cuerpo lampiño al estilo subsahariano, o por su perfil griego. Sirve para predecir propensión hacia ciertas enfermedades de origen genético, como el riesgo de manifestar Parkinson, o de sufrir el síndrome de QT largo, una cardiomiopatía de las más frecuentes. Sirve como cédula de identidad inequívoca, existiendo hoy en día bancos de ADN con las credenciales de los agresores sexuales más violentos. Sirve para guiar el tratamiento y/o la creación de nuevas drogas más eficientes dirigidas hacia un determinado sub-grupo poblacional con un perfil genético particular, lo que se ha llamado medicina personalizada. Hasta sirve para almacenar datos, como si fuera un disco duro [3]. Así uno podría estar un buen rato, enumerando los usos que le hemos dado al conocimiento obtenido de la doble hélice.
De la mano de las herramientas de la biología moderna, nuestro entendimiento sobre el funcionamiento de los genes, sobre las regiones no-codificantes del ADN, y sobre los elementos que conforman la epigenética, están permitiendo reescribir día a día nuestro conocimiento de la genética, la enfermedad y la herencia. Ni la pluma de Jay Kay, ni la clarividencia de Niccol podrían presagiar lo que se viene [4], si se piensa por un momento que hace 64 años, en plena primavera del 53, contábamos con poco más que el esquema que aparece en la figura 1.
[1] Cabe destacar que el ADN de una célula ocupa casi 2 metros de largo si se estira, pero debe caber en un núcleo que tiene 6 micrómetros (0.000006 metros) de diámetro. De allí que se encuentre altamente compactado. Dicha compactación debe liberarse ligeramente por regiones para permitir la síntesis de proteínas. La epigenética regula, entre otras cosas, los niveles locales y globales de compactación de la información genética y su ubicación espacial dentro del núcleo.
[2] Así se denomina a los habitantes de la penillanura uruguaya.
[3] Mientras se terminaba de escribir este artículo, dos científicas del centro de genómica de Nueva York lograron guardar una película de los hermanos Lumière en una molécula de ADN (publicado en Science el 3 de marzo 2017).
[4] El autor se refiere al vocalista de la banda Jamiroquai y al tema "Virtual insanity" del disco "Travelling without moving", y a la película del director Andrew Niccol "Gattaca".
Pablo D. Dans
Es licenciado en Bioquímica, doctor en química teórica (UdelaR) y ostenta 3 posdoctorados. Actualmente es investigador asociado en el IRB Barcelona (España). Su especialidad reside en el desarrollo de modelos biofísicos y fisicoquímicos para estudiar la estructura y la dinámica de los ácidos nucleicos, desde las nucleobases hasta la conformación de los cromosomas. Sus investigaciones sobre ADN y ARN han sido publicadas en revistas de editoriales como Science, Nature, PNAS y Oxford press. Es el primer sudamericano en ser miembro del Ascona B-DNA Consortium. Es miembro asociado del PEDECIBA y del Sistema Nacional de Investigadores (SNI).
pablo.dans@irbbarcelona.org
Por entregas anteriores de nuestra Columna de Ciencia y Tecnología, visite aquí.
UyPress - Agencia Uruguaya de Noticias
Más información en:
https://www.uypress.net/Columnistas/Pablo-D-Dans-uc75966
![]()